Multimodal Language Model for Sign Language Recognition (SLR)
Lionel Pigou / April 2018
Disclaimer: This post is summarized by an AI chatbot and is based on the chapter in my Ph.D dissertation on page 155.

TV broadcasting organizations like the BBC (British Broadcasting Corporation) or the VRT (Flemish Radio and Television Broadcasting Organization) are making news broadcasts accessible to deaf people by overlaying a sign language interpreter on the screen. This creates a large amount of data where spoken language is interpreted into sign language. However, translating sign language to written Dutch is challenging due to the lack of examples and the lack of a one-to-one mapping between sign language and written language. In this chapter, we explore the problem of sign language recognition in TV news broadcasts and propose a model that aligns subtitles with sign language video fragments.
VRT news dataset
We collected a dataset of news videos with Flemish Sign Language interpreter overlays in collaboration with VRT. The dataset contains daily news broadcasts from September 2012 to July 2015, totaling 575 hours of usable and subtitled footage. The interpreter overlay is mixed with the background news broadcast, and there are four different interpreters and two different static backgrounds in the dataset.
Methodology
Our approach involves embedding the source sign language video fragments into a shared vector space using a convolutional neural network (CNN). We leverage an existing Word2Vec model trained on Dutch words to encode the target subtitles into the same vector space. We then calculate the matching scores between the source video fragments and the target words using dot products in the embedding vector space.
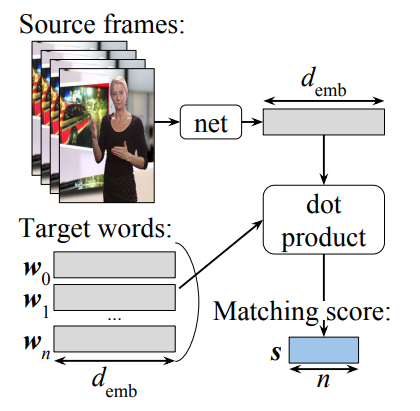
To train the model, we employ a ranking-based objective that aims to maximize the similarity between the video representation and the target subtitles while minimizing the similarity with random subtitles.
Experiments
We preprocess the data by cropping the video frames, converting them to grayscale, and subtracting the previous frame to remove static information. We also filter and clean the subtitles, using a pretrained Word2Vec model for word embeddings. The dataset is split into training, validation, and test sets. We train the model using the Adam update rule and orthogonal weight initialization. The margin loss converges to around 0.9, and the accuracy of matching positive and negative targets reaches approximately 74%.
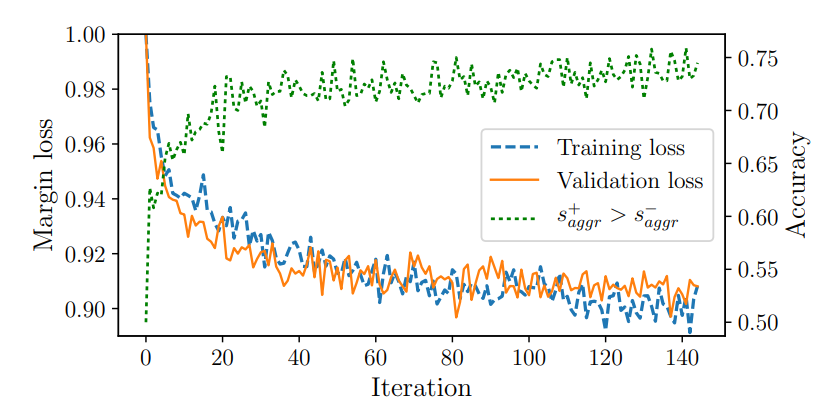
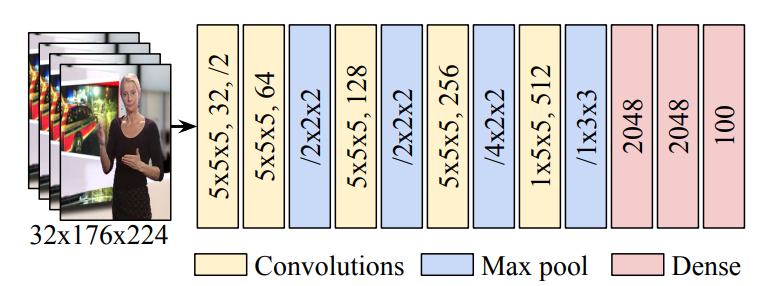
Results
The model shows promising results in predicting the general theme of the video fragments in some cases, with an estimated 25% rate of sensible results in terms of topic. The model also learns certain key points in the vector space, with specific neighboring words consistently emerging for different topics. However, the model’s performance is still far from achieving accurate translation between sign language and written Dutch.

Conclusion
We have developed a model that embeds sign language video fragments into a shared vector space with Dutch subtitles. While the model shows some ability to predict the topic of video fragments and learns specific patterns, the overall results are not yet at the level of accurate translation. Future improvements could involve hand tracking, using pretrained language models for encoding groups of words or sentences, incorporating sign language corpora in training, and exploring larger models.