Gesture and Sign Language Recognition With Temporal Residual Networks
Lionel Pigou / October 2017
Disclaimer: This post is summarized by an AI chatbot and is based on the chapter in my Ph.D dissertation on page 127 and my ICCV 2017 paper.

We explore the field of sign language recognition (SLR) and its application in video corpora. Building upon the success of deep neural networks for gesture recognition, we investigate the recognition of signs from three different video corpora: Corpus VGT (Flemish Sign Language Corpus), Corpus NGT (Sign Language of the Netherlands Corpus), and the ChaLearn LAP RGB-D Continuous Gesture Dataset (ConGD).
The setup consists of three experiments, each focusing on a different aspect of SLR. We begin with isolated sign recognition, where signs are recognized individually. Then, we move on to continuous SLR, where signs are recognized in a continuous sequence of frames. Finally, we explore continuous recognition of gestures and signs using the ChaLearn LAP ConGD dataset.
Sign Language Video Corpora
We describe the three video corpora used in our research: Corpus NGT, Corpus VGT, and ChaLearn LAP ConGD. These corpora contain videos of Deaf signers performing various tasks and are annotated with glosses, representing the sign language vocabulary.
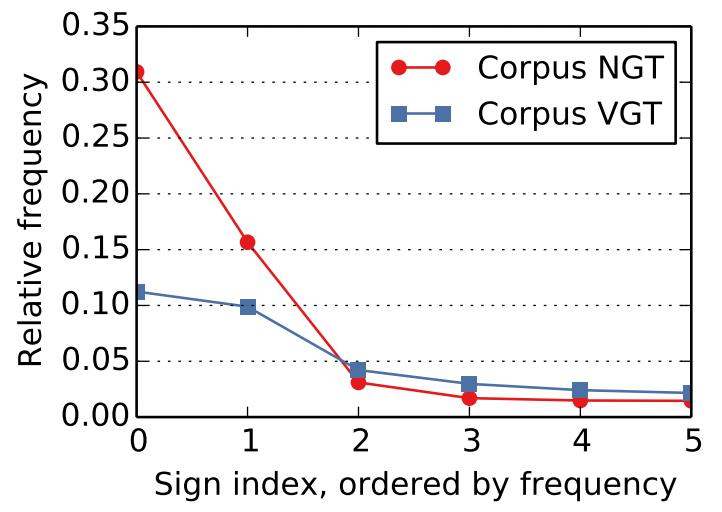
Corpus NGT: Contains videos of Deaf signers using the Sign Language of the Netherlands. It includes narrative and discussion fragments, with annotations created using the ELAN software. The corpus consists of 55,224 video-gloss pairs from 78 different signers.

Corpus VGT: Contains videos of Deaf signers using Flemish Sign Language, with similar tasks and annotations as Corpus NGT. The videos are recorded at 50 frames per second and include 12,599 video-gloss pairs from 53 different signers.
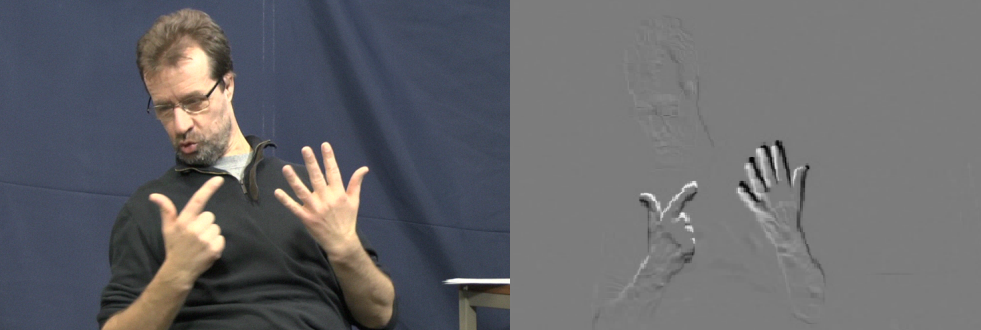
ChaLearn LAP ConGD: A large-scale gesture dataset with gestures from multiple sources, including sign language. The dataset consists of 47,933 gestures performed by 21 individuals, recorded using a Microsoft Kinect camera.

Isolated Sign Recognition
In this section, we focus on recognizing isolated signs in the sign language video corpora. We employ a convolutional neural network (CNN) for classification, training the model to predict the gloss corresponding to a sign clip.
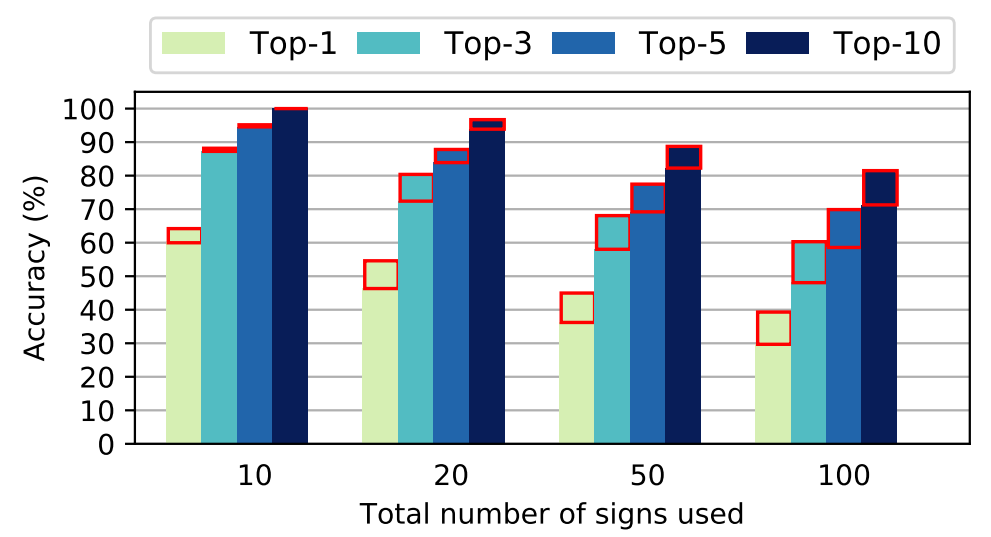
Data preparation involves preprocessing the input frames by converting them to grayscale, resizing them, and subtracting the previous frame to remove static information. The clips are sampled at 6.25 frames per second, and the 100 most frequently used signs are extracted for training, validation, and testing.
The CNN model architecture consists of stacked convolutional layers followed by fully connected layers and a softmax classifier. The model is trained using the Adam optimization algorithm, and data augmentation techniques such as random translations, rotations, and scaling are applied.
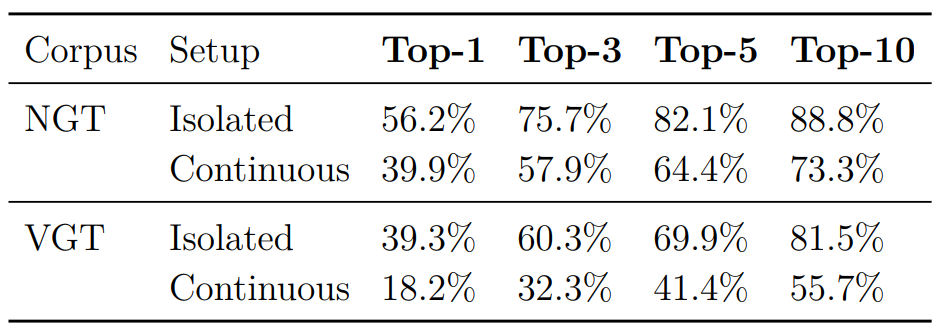
The results for both Corpus NGT and Corpus VGT show promising performance, with top-N accuracies of 56.2% and 39.3% respectively for the 100 most common signs. The confusion matrices reveal that the model tends to confuse less frequent signs with more commonly occurring ones.
Continuous Sign Language Recognition
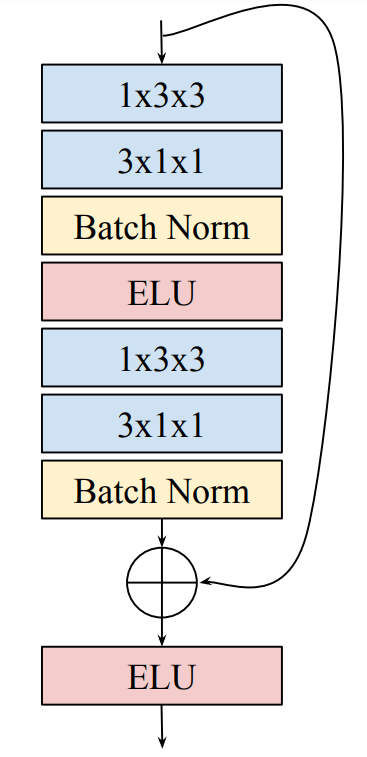
In this section, we tackle the challenge of recognizing signs in a continuous sequence of frames, where the temporal locations of gestures and signs are unknown. We use a frame-by-frame classification approach, employing a residual network architecture with either a many-to-one or many-to-many configuration.
The network architecture includes residual building blocks and incorporates spatial and temporal convolutions to capture motion features. The models are trained end-to-end, optimizing the cross-entropy loss function using gradient descent with the Adam update rule.
For Corpus NGT, the model achieves a top-1 frame-wise accuracy of 39.9%, indicating the correct prediction for individual frames. However, the performance is lower compared to isolated sign recognition, as the task of continuous recognition is more challenging due to the absence of defined sign boundaries.
For Corpus VGT, the model’s performance decreases further, with a top-1 frame-wise accuracy of 18.2%. The smaller amount of annotations in Corpus VGT contributes to the difficulty in training the model for continuous recognition.
Additionally, we participate in the ChaLearn LAP ConGD Challenge and achieve a mean Jaccard index of 0.3164, surpassing the results from the previous round. Although our model does not utilize depth information, it demonstrates competitive performance compared to other methods.
Conclusion and Future Work
In conclusion, deep neural networks, specifically CNNs and residual networks, show potential for SLR in video corpora. The models perform well in isolated sign recognition and show promising results in continuous sign recognition, although the latter is more challenging. Future improvements can be achieved by incorporating depth information, unsupervised feature learning, pretrained weights from large image datasets, hand and arm tracking methods, and language models to enhance context-based predictions in SLR.
Overall, our research contributes to the development of SLR systems and demonstrates the potential of deep neural networks in understanding and recognizing sign language from video data.