Gesture Recognition Using Convolutional Neural Networks
Lionel Pigou / January 2015
Disclaimer: This post is summarized by an AI chatbot and is based on my ECCV paper.

There is an undeniable communication problem between the Deaf community and the hearing majority. Innovations in automatic sign language recognition try to tear down this communication barrier. Our contribution considers a recognition system using the Microsoft Kinect, convolutional neural networks (CNNs) and GPU acceleration. Instead of constructing complex handcrafted features, CNNs are able to automate the process of feature construction. We are able to recognize 20 Italian gestures with high accuracy. The predictive model is able to generalize on users and surroundings not occurring during training with a cross-validation accuracy of 91.7%. Our model achieves a mean Jaccard Index of 0.789 in the ChaLearn 2014 Looking at People gesture spotting competition.
Methodology
The authors used the ChaLearn Looking at People 2014 (CLAP14) dataset, specifically Track 3: Gesture Spotting, which consists of 20 different Italian gestures performed by 27 users. The dataset provides depth maps, user index information, and joint positions captured by the Microsoft Kinect.
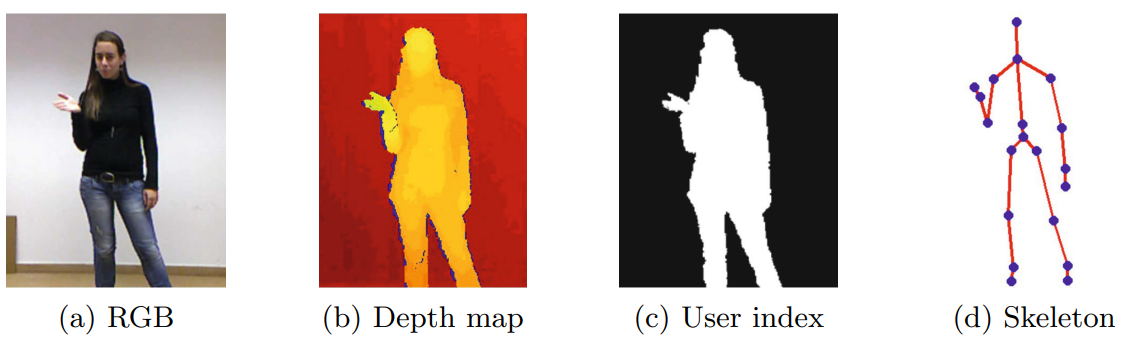
The preprocessing stage involved cropping the highest hand and upper body using joint information. The highest hand was considered the most interesting for recognition. The depth maps were processed to reduce noise, and the resulting videos were resized to 64x64x32 resolution.

CNNs were used for feature extraction, inspired by the visual cortex of the human brain. The CNN architecture included two separate networks for extracting hand and upper body features. Each CNN had three layers, followed by a classical artificial neural network (ANN) with one hidden layer for classification. Local contrast normalization and rectified linear units (ReLUs) were applied in the layers.
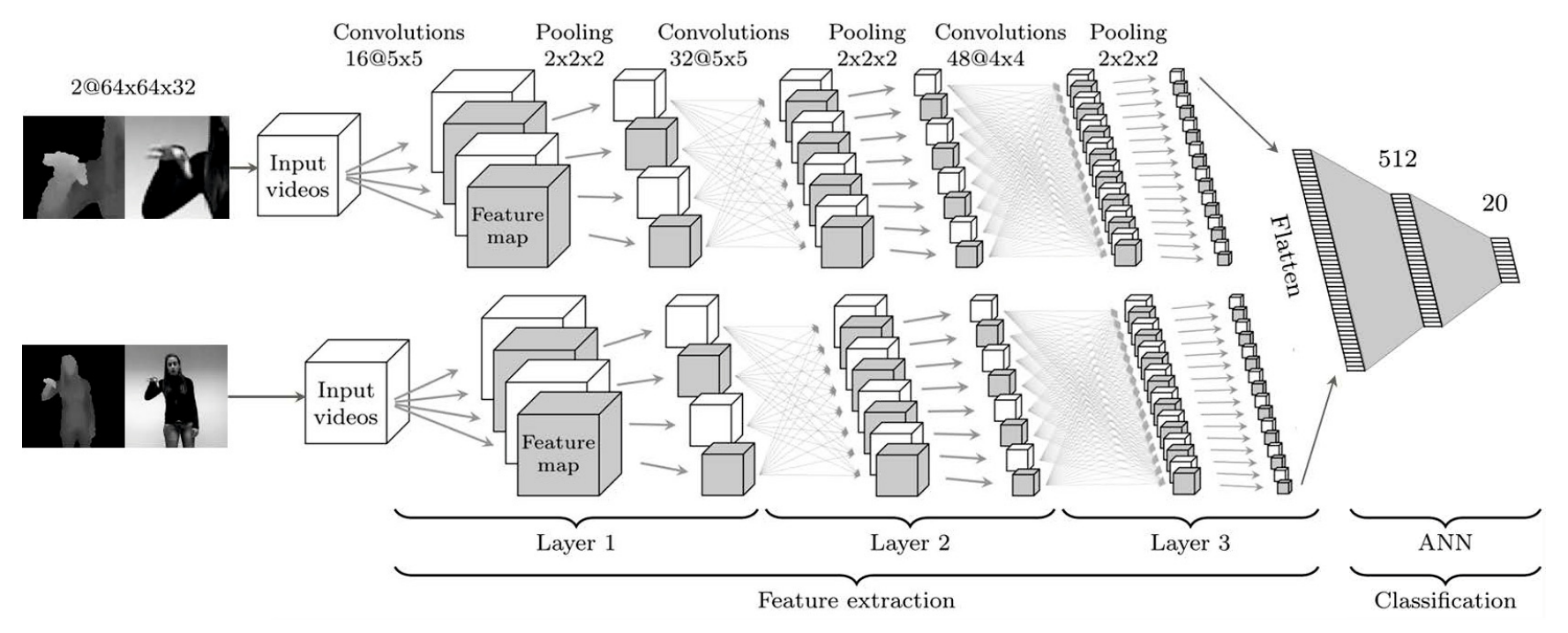
To reduce overfitting, dropout and data augmentation techniques were used during training. Nesterov’s accelerated gradient descent was employed as the optimization algorithm. The models were implemented using Python libraries, Theano and PyLearn2.
The temporal segmentation method aimed to predict the beginning and end frames of each gesture in the video samples. Sliding windows technique was utilized, and consecutive intervals with identical classes and high classification probability were considered as gesture segments.
Results
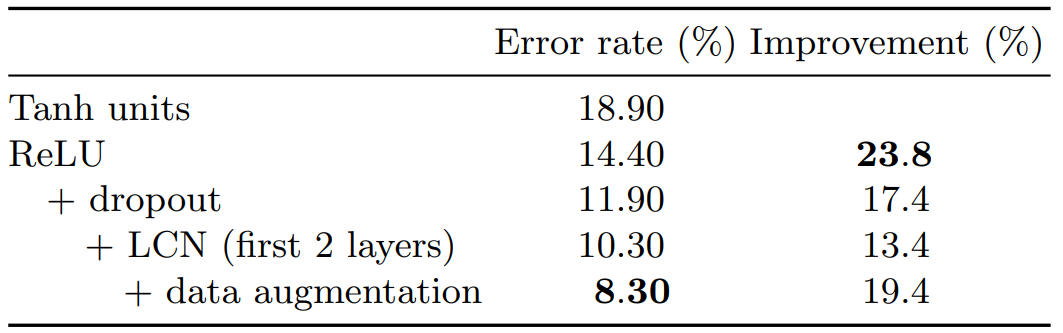
The experiments showed that the models with ReLUs, dropout, local contrast normalization, and data augmentation achieved the best performance. The validation accuracy of the best model was 91.7% (8.3% error rate). The accuracy on the test set was 95.68%, with a 4.13% false positive rate caused by noise movements. The model achieved a mean Jaccard Index of 0.789 in the ChaLearn 2014 competition, ranking fifth out of 17 qualified teams.
Conclusion
The study demonstrates the effectiveness of convolutional neural networks in accurately recognizing sign language gestures, even for users and surroundings not encountered during training. The generalization capabilities of CNNs in spatio-temporal data contribute to the research field of automatic sign language recognition.